Cross Data Center Replication (CDCR) allows you to create multiple SolrCloud data centers and keep them in sync in case they are needed at a future time.
The SolrCloud architecture is not particularly well suited for situations where a single SolrCloud cluster consists of nodes in separated data clusters connected by an expensive pipe. The root problem is that SolrCloud is designed to support Near Real Time Searching by immediately forwarding updates between nodes in the cluster on a per-shard basis. "CDCR" features exist to help mitigate the risk of an entire data center outage.
What is CDCR?
CDCR supports replicating data from one data center to multiple data centers. The initial version of the solution supports an active-passive scenario where data updates are replicated from a Source data center to one or more target data centers.
The target data center(s) will not propagate updates such as adds, updates, or deletes to the source data center and updates should not be sent to any of the target data center(s).
Source and target data centers can serve search queries when CDCR is operating. The target data centers will have slightly stale views of the corpus due to propagation delays, but this is minimal (perhaps a few seconds).
Data changes on the source data center are replicated to the target data center only after they are persisted to disk. The data changes can be replicated in near real-time (with a small delay) or could be scheduled to be sent in intervals to the target data center. This solution pre-supposes that the source and target data centers begin with the same documents indexed. Of course the indexes may be empty to start.
Each shard leader in the source data center will be responsible for replicating its updates to the corresponding leader in the target data center. When receiving updates from the source data center, shard leaders in the target data center will replicate the changes to their own replicas.
This replication model is designed to tolerate some degradation in connectivity, accommodate limited bandwidth, and support batch updates to optimize communication.
Replication supports both a new empty index and pre-built indexes. In the scenario where the replication is set up on a pre-built index, CDCR will ensure consistency of the replication of the updates, but cannot ensure consistency on the full index. Therefore any index created before CDCR was set up will have to be replicated by other means (described in the section Initial Startup) so source and target indexes are fully consistent.
The active-passive nature of the initial implementation implies a "push" model from the source collection to the target collection. Therefore, the source configuration must be able to "see" the ZooKeeper ensemble in the target cluster. The ZooKeeper ensemble is provided configured in the Source’s solrconfig.xml file.
CDCR is configured to replicate from collections in the source cluster to collections in the target cluster on a collection-by-collection basis. Since CDCR is configured in solrconfig.xml (on both source and target clusters), the settings can be tailored for the needs of each collection.
CDCR can be configured to replicate from one collection to a second collection within the same cluster. That is a specialized scenario not covered in this document.
CDCR Glossary
Terms used in this document include:
- Node
-
A JVM instance running Solr; a server.
- Cluster
-
A set of Solr nodes managed as a single unit by a ZooKeeper ensemble, hosting one or more Collections.
- Data Center
-
A group of networked servers hosting a Solr cluster. In this document, the terms Cluster and Data Center are interchangeable as we assume that each Solr cluster is hosted in a different group of networked servers.
- Shard
-
A sub-index of a single logical collection. This may be spread across multiple nodes of the cluster. Each shard can have as many replicas as needed.
- Leader
-
Each shard has one node identified as its leader. All the writes for documents belonging to a shard are routed through the leader.
- Replica
-
A copy of a shard for use in failover or load balancing. Replicas comprising a shard can either be leaders or non-leaders.
- Follower
-
A convenience term for a replica that is not the leader of a shard.
- Collection
-
Multiple documents that make up one logical index. A cluster can have multiple collections.
- Updates Log
-
An append-only log of write operations maintained by each node.
CDCR Architecture
Here is a picture of the data flow.
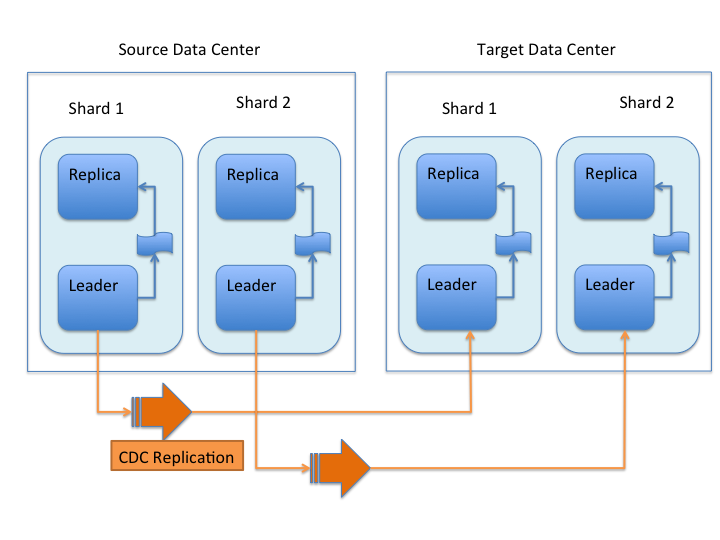
Updates and deletes are first written to the Source cluster, then forwarded to the Target cluster. The data flow sequence is:
-
A shard leader receives a new data update that is processed by its update processor chain.
-
The data update is first applied to the local index.
-
Upon successful application of the data update on the local index, the data update is added to the Updates Log queue.
-
After the data update is persisted to disk, the data update is sent to the replicas within the data center.
-
After Step 4 is successful, CDCR reads the data update from the Updates Log and pushes it to the corresponding collection in the target data center. This is necessary in order to ensure consistency between the Source and target data centers.
-
The leader on the target data center writes the data locally and forwards it to all its followers.
Steps 1, 2, 3 and 4 are performed synchronously by SolrCloud; Step 5 is performed asynchronously by a background thread. Given that CDCR replication is performed asynchronously, it becomes possible to push batch updates in order to minimize network communication overhead. Also, if CDCR is unable to push the update at a given time, for example, due to a degradation in connectivity, it can retry later without any impact on the source data center.
One implication of the architecture is that the leaders in the source cluster must be able to "see" the leaders in the target cluster. Since leaders may change, this effectively means that all nodes in the source cluster must be able to "see" all Solr nodes in the target cluster so firewalls, ACL rules, etc. must be configured with care.
The current design works most robustly if both the Source and target clusters have the same number of shards. There is no requirement that the shards in the Source and target collection have the same number of replicas.
Having different numbers of shards on the Source and target cluster is possible, but is also an "expert" configuration as that option imposes certain constraints and is not recommended. Most of the scenarios where having differing numbers of shards are contemplated are better accomplished by hosting multiple shards on each target Solr instance.
Major Components of CDCR
There are a number of key features and components in CDCR’s architecture:
CDCR Configuration
In order to configure CDCR, the Source data center requires the host address of the ZooKeeper cluster associated with the target data center. The ZooKeeper host address is the only information needed by CDCR to instantiate the communication with the target Solr cluster. The CDCR configuration file on the source cluster will therefore contain a list of ZooKeeper hosts. The CDCR configuration file might also contain secondary/optional configuration, such as the number of CDC Replicator threads, batch updates related settings, etc.
CDCR Initialization
CDCR supports incremental updates to either new or existing collections. CDCR may not be able to keep up with very high volume updates, especially if there are significant communications latencies due to a slow "pipe" between the data centers. Some scenarios:
-
There is an initial bulk load of a corpus followed by lower volume incremental updates. In this case, one can do the initial bulk load and then enable CDCR. See the section Initial Startup for more information.
-
The index is being built up from scratch, without a significant initial bulk load. CDCR can be set up on empty collections and keep them synchronized from the start.
-
The index is always being updated at a volume too high for CDCR to keep up. This is especially possible in situations where the connection between the Source and target data centers is poor. This scenario is unsuitable for CDCR in its current form.
Inter-Data Center Communication
Communication between data centers will be achieved through HTTP and the Solr REST API using the SolrJ client. The SolrJ client will be instantiated with the ZooKeeper host of the target data center. SolrJ will manage the shard leader discovery process.
Updates Tracking & Pushing
CDCR replicates data updates from the source to the target data center by leveraging the Updates Log.
A background thread regularly checks the Updates Log for new entries, and then forwards them to the target data center. The thread therefore needs to keep a checkpoint in the form of a pointer to the last update successfully processed in the Updates Log. Upon acknowledgement from the target data center that updates have been successfully processed, the Updates Log pointer is updated to reflect the current checkpoint.
This pointer must be synchronized across all the replicas. In the case where the leader goes down and a new leader is elected, the new leader will be able to resume replication from the last update by using this synchronized pointer. The strategy to synchronize such a pointer across replicas will be explained next.
If for some reason, the target data center is offline or fails to process the updates, the thread will periodically try to contact the target data center and push the updates.
Synchronization of Update Checkpoints
A reliable synchronization of the update checkpoints between the shard leader and shard replicas is critical to avoid introducing inconsistency between the Source and target data centers. Another important requirement is that the synchronization must be performed with minimal network traffic to maximize scalability.
In order to achieve this, the strategy is to:
-
Uniquely identify each update operation. This unique identifier will serve as pointer.
-
Rely on two storages: an ephemeral storage on the Source shard leader, and a persistent storage on the target cluster.
The shard leader in the source cluster will be in charge of generating a unique identifier for each update operation, and will keep a copy of the identifier of the last processed updates in memory. The identifier will be sent to the target cluster as part of the update request. On the target data center side, the shard leader will receive the update request, store it along with the unique identifier in the Updates Log, and replicate it to the other shards.
SolrCloud already provides a unique identifier for each update operation, i.e., a “version” number. This version number is generated using a time-based lmport clock which is incremented for each update operation sent. This provides an “happened-before” ordering of the update operations that will be leveraged in (1) the initialization of the update checkpoint on the source cluster, and in (2) the maintenance strategy of the Updates Log.
The persistent storage on the target cluster is used only during the election of a new shard leader on the Source cluster. If a shard leader goes down on the source cluster and a new leader is elected, the new leader will contact the target cluster to retrieve the last update checkpoint and instantiate its ephemeral pointer. On such a request, the target cluster will retrieve the latest identifier received across all the shards, and send it back to the source cluster. To retrieve the latest identifier, every shard leader will look up the identifier of the first entry in its Update Logs and send it back to a coordinator. The coordinator will have to select the highest among them.
This strategy does not require any additional network traffic and ensures reliable pointer synchronization. Consistency is principally achieved by leveraging SolrCloud. The update workflow of SolrCloud ensures that every update is applied to the leader but also to any of the replicas. If the leader goes down, a new leader is elected. During the leader election, a synchronization is performed between the new leader and the other replicas. As a result, this ensures that the new leader has a consistent Update Logs with the previous leader. Having a consistent Updates Log means that:
-
On the source cluster, the update checkpoint can be reused by the new leader.
-
On the target cluster, the update checkpoint will be consistent between the previous and new leader. This ensures the correctness of the update checkpoint sent by a newly elected leader from the target cluster.
Maintenance of Updates Log
The CDCR replication logic requires modification to the maintenance logic of the Updates Log on the source data center. Initially, the Updates Log acts as a fixed size queue, limited to 100 update entries. In the CDCR scenario, the Update Logs must act as a queue of variable size as they need to keep track of all the updates up through the last processed update by the target data center. Entries in the Update Logs are removed only when all pointers (one pointer per target data center) are after them.
If the communication with one of the target data center is slow, the Updates Log on the source data center can grow to a substantial size. In such a scenario, it is necessary for the Updates Log to be able to efficiently find a given update operation given its identifier. Given that its identifier is an incremental number, it is possible to implement an efficient search strategy. Each transaction log file contains as part of its filename the version number of the first element. This is used to quickly traverse all the transaction log files and find the transaction log file containing one specific version number.
Monitoring
CDCR provides the following monitoring capabilities over the replication operations:
-
Monitoring of the outgoing and incoming replications, with information such as the Source and target nodes, their status, etc.
-
Statistics about the replication, with information such as operations (add/delete) per second, number of documents in the queue, etc.
Information about the lifecycle and statistics will be provided on a per-shard basis by the CDC Replicator thread. The CDCR API can then aggregate this information an a collection level.
CDC Replicator
The CDC Replicator is a background thread that is responsible for replicating updates from a Source data center to one or more target data centers. It is responsible in providing monitoring information on a per-shard basis. As there can be a large number of collections and shards in a cluster, we will use a fixed-size pool of CDC Replicator threads that will be shared across shards.
Limitations
The current design of CDCR has some limitations. CDCR will continue to evolve over time and many of these limitations will be addressed. Among them are:
-
CDCR is unlikely to be satisfactory for bulk-load situations where the update rate is high, especially if the bandwidth between the Source and target clusters is restricted. In this scenario, the initial bulk load should be performed, the Source and target data centers synchronized and CDCR be utilized for incremental updates.
-
CDCR is currently only active-passive; data is pushed from the Source cluster to the target cluster. There is active work being done in this area in the 6x code line to remove this limitation.
-
CDCR works most robustly with the same number of shards in the Source and target collection. The shards in the two collections may have different numbers of replicas.
Configuration
The source and target configurations differ in the case of the data centers being in separate clusters. "Cluster" here means separate ZooKeeper ensembles controlling disjoint Solr instances. Whether these data centers are physically separated or not is immaterial for this discussion.
Source Configuration
Here is a sample of a source configuration file, a section in solrconfig.xml. The presence of the <replica> section causes CDCR to use this cluster as the Source and should not be present in the target collections in the cluster-to-cluster case. Details about each setting are after the two examples:
<requestHandler name="/cdcr" class="solr.CdcrRequestHandler">
<lst name="replica">
<str name="zkHost">10.240.18.211:2181</str>
<str name="source">collection1</str>
<str name="target">collection1</str>
</lst>
<lst name="replicator">
<str name="threadPoolSize">8</str>
<str name="schedule">1000</str>
<str name="batchSize">128</str>
</lst>
<lst name="updateLogSynchronizer">
<str name="schedule">1000</str>
</lst>
</requestHandler>
<!-- Modify the <updateLog> section of your existing <updateHandler>
in your config as below -->
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog class="solr.CdcrUpdateLog">
<str name="dir">${solr.ulog.dir:}</str>
<!--Any parameters from the original <updateLog> section -->
</updateLog>
</updateHandler>Target Configuration
Here is a typical target configuration.
Target instance must configure an update processor chain that is specific to CDCR. The update processor chain must include the CdcrUpdateProcessorFactory. The task of this processor is to ensure that the version numbers attached to update requests coming from a CDCR source SolrCloud are reused and not overwritten by the target. A properly configured Target configuration looks similar to this.
<requestHandler name="/cdcr" class="solr.CdcrRequestHandler">
<lst name="buffer">
<str name="defaultState">disabled</str>
</lst>
</requestHandler>
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">cdcr-processor-chain</str>
</lst>
</requestHandler>
<updateRequestProcessorChain name="cdcr-processor-chain">
<processor class="solr.CdcrUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>
<!-- Modify the <updateLog> section of your existing <updateHandler> in your
config as below -->
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog class="solr.CdcrUpdateLog">
<str name="dir">${solr.ulog.dir:}</str>
<!--Any parameters from the original <updateLog> section -->
</updateLog>
</updateHandler>Configuration Details
The configuration details, defaults and options are as follows:
The Replica Element
CDCR can be configured to forward update requests to one or more replicas. A replica is defined with a “replica” list as follows:
| Parameter | Required | Default | Description |
|---|---|---|---|
zkHost |
Yes |
none |
The host address for ZooKeeper of the target SolrCloud. Usually this is a comma-separated list of addresses to each node in the target ZooKeeper ensemble. |
Source |
Yes |
none |
The name of the collection on the Source SolrCloud to be replicated. |
Target |
Yes |
none |
The name of the collection on the target SolrCloud to which updates will be forwarded. |
The Replicator Element
The CDC Replicator is the component in charge of forwarding updates to the replicas. The replicator will monitor the update logs of the Source collection and will forward any new updates to the target collection.
The replicator uses a fixed thread pool to forward updates to multiple replicas in parallel. If more than one replica is configured, one thread will forward a batch of updates from one replica at a time in a round-robin fashion. The replicator can be configured with a “replicator” list as follows:
| Parameter | Required | Default | Description |
|---|---|---|---|
threadPoolSize |
No |
2 |
The number of threads to use for forwarding updates. One thread per replica is recommended. |
schedule |
No |
10 |
The delay in milliseconds for the monitoring the update log(s). |
batchSize |
No |
128 |
The number of updates to send in one batch. The optimal size depends on the size of the documents. Large batches of large documents can increase your memory usage significantly. |
The updateLogSynchronizer Element
Expert: Non-leader nodes need to synchronize their update logs with their leader node from time to time in order to clean deprecated transaction log files. By default, such a synchronization process is performed every minute. The schedule of the synchronization can be modified with a “updateLogSynchronizer” list as follows:
| Parameter | Required | Default | Description |
|---|---|---|---|
schedule |
No |
60000 |
The delay in milliseconds for synchronizing the updates log. |
The Buffer Element
CDCR is configured by default to buffer any new incoming updates. When buffering updates, the updates log will store all the updates indefinitely. Replicas do not need to buffer updates, and it is recommended to disable buffer on the target SolrCloud. The buffer can be disabled at startup with a “buffer” list and the parameter “defaultState” as follows:
| Parameter | Required | Default | Description |
|---|---|---|---|
defaultState |
No |
enabled |
The state of the buffer at startup. |
CDCR API
The CDCR API is used to control and monitor the replication process. Control actions are performed at a collection level, i.e., by using the following base URL for API calls: http://localhost:8983/solr/<collection>.
Monitor actions are performed at a core level, i.e., by using the following base URL for API calls: http://localhost:8983/solr/<collection>.
Currently, none of the CDCR API calls have parameters.
API Entry Points (Control)
-
<collection>/cdcr?action=STATUS: Returns the current state of CDCR. -
<collection>/cdcr?action=START: Starts CDCR replication -
<collection>/cdcr?action=STOP: Stops CDCR replication. -
<collection>/cdcr?action=ENABLEBUFFER: Enables the buffering of updates. -
<collection>/cdcr?action=DISABLEBUFFER: Disables the buffering of updates.
API Entry Points (Monitoring)
-
core/cdcr?action=QUEUES: Fetches statistics about the queue for each replica and about the update logs. -
core/cdcr?action=OPS: Fetches statistics about the replication performance (operations per second) for each replica. -
core/cdcr?action=ERRORS: Fetches statistics and other information about replication errors for each replica.
Control Commands
STATUS
/collection/cdcr?action=STATUS
Input
Query Parameters: There are no parameters to this command.
Output
Output Content
The current state of the CDCR, which includes the state of the replication process and the state of the buffer.
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=STATUSOutput
{
"responseHeader": {
"status": 0,
"QTime": 0
},
"status": {
"process": "stopped",
"buffer": "enabled"
}
}ENABLEBUFFER
/collection/cdcr?action=ENABLEBUFFER
Input
Query Parameters: There are no parameters to this command.
Output
Output Content
The status of the process and an indication of whether the buffer is enabled
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=ENABLEBUFFEROutput
{
"responseHeader": {
"status": 0,
"QTime": 0
},
"status": {
"process": "started",
"buffer": "enabled"
}
}DISABLEBUFFER
/collection/cdcr?action=DISABLEBUFFER
Input
Query Parameters: There are no parameters to this command
Output
Output Content: The status of CDCR and an indication that the buffer is disabled.
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=DISABLEBUFFEROutput
{
"responseHeader": {
"status": 0,
"QTime": 0
},
"status": {
"process": "started",
"buffer": "disabled"
}
}START
/collection/cdcr?action=START
Input
Query Parameters: There are no parameters for this action
Output
Output Content: Confirmation that CDCR is started and the status of buffering
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=STARTOutput
{
"responseHeader": {
"status": 0,
"QTime": 0
},
"status": {
"process": "started",
"buffer": "enabled"
}
}STOP
/collection/cdcr?action=STOP
Input
Query Parameters: There are no parameters for this command.
Output
Output Content: The status of CDCR, including the confirmation that CDCR is stopped
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=STOPOutput
{
"responseHeader": {
"status": 0,
"QTime": 0
},
"status": {
"process": "stopped",
"buffer": "enabled"
}
}Monitoring commands
QUEUES
/core/cdcr?action=QUEUES
Input
Query Parameters: There are no parameters for this command
Output
Output Content
The output is composed of a list “queues” which contains a list of (ZooKeeper) target hosts, themselves containing a list of target collections. For each collection, the current size of the queue and the timestamp of the last update operation successfully processed is provided. The timestamp of the update operation is the original timestamp, i.e., the time this operation was processed on the Source SolrCloud. This allows an estimate the latency of the replication process.
The “queues” object also contains information about the updates log, such as the size (in bytes) of the updates log on disk (“tlogTotalSize”), the number of transaction log files (“tlogTotalCount”) and the status of the updates log synchronizer (“updateLogSynchronizer”).
Examples
Input
http://host:8983/solr/<replica_name>/cdcr?action=QUEUESOutput
{
"responseHeader":{
"status": 0,
"QTime": 1
},
"queues":{
"127.0.0.1: 40342/solr":{
"Target_collection":{
"queueSize": 104,
"lastTimestamp": "2014-12-02T10:32:15.879Z"
}
}
},
"tlogTotalSize":3817,
"tlogTotalCount":1,
"updateLogSynchronizer": "stopped"
}OPS
/core/cdcr?action=OPS
Input
Query Parameters: There are no parameters for this command.
Output
Output Content: The output is composed of a list “operationsPerSecond” which contains a list of (ZooKeeper) target hosts, themselves containing a list of target collections. For each collection, the average number of processed operations per second since the start of the replication process is provided. The operations are further broken down into two groups: add and delete operations.
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=OPSOutput
{
"responseHeader":{
"status":0,
"QTime":1
},
"operationsPerSecond":{
"127.0.0.1: 59661/solr":{
"Target_collection":{
"all": 297.102944952749052,
"adds": 297.102944952749052,
"deletes": 0.0
}
}
}
}ERRORS
/core/cdcr?action=ERRORS
Input
Query Parameters: There are no parameters for this command.
Output
Output Content: The output is composed of a list “errors” which contains a list of (ZooKeeper) target hosts, themselves containing a list of target collections. For each collection, information about errors encountered during the replication is provided, such as the number of consecutive errors encountered by the replicator thread, the number of bad requests or internal errors since the start of the replication process, and a list of the last errors encountered ordered by timestamp.
Examples
Input
http://host:8983/solr/<collection_name>/cdcr?action=ERRORSOutput
{
"responseHeader":{
"status":0,
"QTime":2
},
"errors": {
"127.0.0.1: 36872/solr":{
"Target_collection":{
"consecutiveErrors":3,
"bad_request":0,
"internal":3,
"last":{
"2014-12-02T11:04:42.523Z":"internal",
"2014-12-02T11:04:39.223Z":"internal",
"2014-12-02T11:04:38.22Z":"internal"
}
}
}
}
}Initial Startup
This is a general approach for initializing CDCR in a production environment based upon an approach taken by the initial working installation of CDCR and generously contributed to illustrate a "real world" scenario.
-
Customer uses the CDCR approach to keep a remote disaster-recovery instance available for production backup. This is an active-passive solution.
-
Customer has 26 clouds with 200 million assets per cloud (15GB indexes). Total document count is over 4.8 billion.
-
Source and target clouds were synched in 2-3 hour maintenance windows to establish the base index for the targets.
-
As usual, it is good to start small. Sync a single cloud and monitor for a period of time before doing the others. You may need to adjust your settings several times before finding the right balance.
-
Before starting, stop or pause the indexers. This is best done during a small maintenance window.
-
Stop the SolrCloud instances at the Source
-
Include the CDCR request handler configuration in
solrconfig.xmlas in the below example.<requestHandler name="/cdcr" class="solr.CdcrRequestHandler"> <lst name="replica"> <str name="zkHost">${TargetZk}</str> <str name="Source">${SourceCollection}</str> <str name="Target">${TargetCollection}</str> </lst> <lst name="replicator"> <str name="threadPoolSize">8</str> <str name="schedule">10</str> <str name="batchSize">2000</str> </lst> <lst name="updateLogSynchronizer"> <str name="schedule">1000</str> </lst> </requestHandler> <updateRequestProcessorChain name="cdcr-processor-chain"> <processor class="solr.CdcrUpdateProcessorFactory" /> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain> -
Upload the modified
solrconfig.xmlto ZooKeeper on both Source and Target -
Sync the index directories from the Source collection to target collection across to the corresponding shard nodes.
rsyncworks well for this.For example, if there are 2 shards on collection1 with 2 replicas for each shard, copy the corresponding index directories from
shard1replica1Source
to
shard1replica1Target
shard1replica2Source
to
shard1replica2Target
shard2replica1Source
to
shard2replica1Target
shard2replica2Source
to
shard2replica2Target
-
Start the ZooKeeper on the Target (DR) side
-
Start the SolrCloud on the Target (DR) side
-
Start the ZooKeeper on the Source side
-
Start the SolrCloud on the Source side. As a general rule, the Target (DR) side of the SolrCloud should be started before the Source side.
-
Activate the CDCR on Source instance using the CDCR API:
http://host:port/solr/collection_name/cdcr?action=STARThttp://host:port/solr/<collection_name>/cdcr?action=START -
There is no need to run the /cdcr?action=START command on the Target
-
Disable the buffer on the Target
http://host:port/solr/collection_name/cdcr?action=DISABLEBUFFER -
Renable indexing
Monitoring
-
Network and disk space monitoring are essential. Ensure that the system has plenty of available storage to queue up changes if there is a disconnect between the Source and Target. A network outage between the two data centers can cause your disk usage to grow.
-
Tip: Set a monitor for your disks to send alerts when the disk gets over a certain percentage (e.g., 70%)
-
Tip: Run a test. With moderate indexing, how long can the system queue changes before you run out of disk space?
-
-
Create a simple way to check the counts between the Source and the Target.
-
Keep in mind that if indexing is running, the Source and Target may not match document for document. Set an alert to fire if the difference is greater than some percentage of the overall cloud size.
-
ZooKeeper Settings
With CDCR, the target ZooKeepers will have connections from the Target clouds and the Source clouds. You may need to increase the maxClientCnxns setting in zoo.cfg.
## set numbers of connection to 200 from client
## is maxClientCnxns=0 that means no limit
maxClientCnxns=800Upgrading and Patching Production
When rolling in upgrades to your indexer or application, you should shutdown the Source (production) and the Target (DR). Depending on your setup, you may want to pause/stop indexing. Deploy the release or patch and renable indexing. Then start the Target (DR).
-
There is no need to reissue the DISABLEBUFFERS or START commands. These are persisted.
-
After starting the Target, run a simple test. Add a test document to each of the Source clouds. Then check for it on the Target.
#send to the Source
curl http://<Source>/solr/cloud1/update -H 'Content-type:application/json' -d '[{"SKU":"ABC"}]'
#check the Target
curl "http://<Target>:8983/solr/<collection_name>/select?q=SKU:ABC&wt=json&indent=true"Limitations
-
Running CDCR with the indexes on HDFS is not currently supported, see: Solr CDCR over HDFS.