Index Replication distributes complete copies of a master index to one or more slave servers. The master server continues to manage updates to the index. All querying is handled by the slaves. This division of labor enables Solr to scale to provide adequate responsiveness to queries against large search volumes.
The figure below shows a Solr configuration using index replication. The master server’s index is replicated on the slaves.
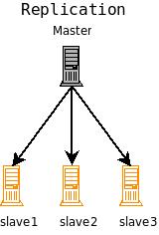
Index Replication in Solr
Solr includes a Java implementation of index replication that works over HTTP:
-
The configuration affecting replication is controlled by a single file,
solrconfig.xml -
Supports the replication of configuration files as well as index files
-
Works across platforms with same configuration
-
No reliance on OS-dependent file system features (e.g., hard links)
-
Tightly integrated with Solr; an admin page offers fine-grained control of each aspect of replication
-
The Java-based replication feature is implemented as a request handler. Configuring replication is therefore similar to any normal request handler.
|
Replication In SolrCloud
Although there is no explicit concept of "master/slave" nodes in a SolrCloud cluster, the When using SolrCloud, the |
Replication Terminology
The table below defines the key terms associated with Solr replication.
- Index
-
A Lucene index is a directory of files. These files make up the searchable and returnable data of a Solr Core.
- Distribution
-
The copying of an index from the master server to all slaves. The distribution process takes advantage of Lucene’s index file structure.
- Inserts and Deletes
-
As inserts and deletes occur in the index, the directory remains unchanged. Documents are always inserted into newly created segment files. Documents that are deleted are not removed from the segment files. They are flagged in the file, deletable, and are not removed from the segments until the segment is merged as part of normal index updates.
- Master and Slave
-
A Solr replication master is a single node which receives all updates initially and keeps everything organized. Solr replication slave nodes receive no updates directly, instead all changes (such as inserts, updates, deletes, etc.) are made against the single master node. Changes made on the master are distributed to all the slave nodes which service all query requests from the clients.
- Update
-
An update is a single change request against a single Solr instance. It may be a request to delete a document, add a new document, change a document, delete all documents matching a query, etc. Updates are handled synchronously within an individual Solr instance.
- Optimization
-
A process that compacts the index and merges segments in order to improve query performance. Optimization should only be run on the master nodes. An optimized index may give query performance gains compared to an index that has become fragmented over a period of time with many updates. Distributing an optimized index requires a much longer time than the distribution of new segments to an un-optimized index.
| optimizing is not recommended unless it can be performed regularly as it may lead to a significantly larger portion of the index consisting of deleted documents than would normally be the case. |
- Segments
-
A self contained subset of an index consisting of some documents and data structures related to the inverted index of terms in those documents.
- mergeFactor
-
A parameter that controls the number of segments in an index. For example, when mergeFactor is set to 3, Solr will fill one segment with documents until the limit maxBufferedDocs is met, then it will start a new segment. When the number of segments specified by mergeFactor is reached (in this example, 3) then Solr will merge all the segments into a single index file, then begin writing new documents to a new segment.
- Snapshot
-
A directory containing hard links to the data files of an index. Snapshots are distributed from the master nodes when the slaves pull them, "smart copying" any segments the slave node does not have in snapshot directory that contains the hard links to the most recent index data files.
Configuring the ReplicationHandler
In addition to ReplicationHandler configuration options specific to the master/slave roles, there are a few special configuration options that are generally supported (even when using SolrCloud).
-
maxNumberOfBackupsan integer value dictating the maximum number of backups this node will keep on disk as it receivesbackupcommands. -
Similar to most other request handlers in Solr you may configure a set of defaults, invariants, and/or appends parameters corresponding with any request parameters supported by the
ReplicationHandlerwhen processing commands.
Configuring the Replication RequestHandler on a Master Server
Before running a replication, you should set the following parameters on initialization of the handler:
replicateAfter-
String specifying action after which replication should occur. Valid values are commit, optimize, or startup. There can be multiple values for this parameter. If you use "startup", you need to have a "commit" and/or "optimize" entry also if you want to trigger replication on future commits or optimizes.
backupAfter
String specifying action after which a backup should occur. Valid values are commit, optimize, or startup. There can be multiple values for this parameter. It is not required for replication, it just makes a backup.
maxNumberOfBackups
Integer specifying how many backups to keep. This can be used to delete all but the most recent N backups.
confFiles-
The configuration files to replicate, separated by a comma.
commitReserveDuration-
If your commits are very frequent and your network is slow, you can tweak this parameter to increase the amount of time expected to be required to transfer data. The default is
00:00:10i.e., 10 seconds.
The example below shows a possible 'master' configuration for the ReplicationHandler, including a fixed number of backups and an invariant setting for the maxWriteMBPerSec request parameter to prevent slaves from saturating its network interface
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="master">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
<str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str>
</lst>
<int name="maxNumberOfBackups">2</int>
<str name="commitReserveDuration">00:00:10</str>
<lst name="invariants">
<str name="maxWriteMBPerSec">16</str>
</lst>
</requestHandler>Replicating solrconfig.xml
In the configuration file on the master server, include a line like the following:
<str name="confFiles">solrconfig_slave.xml:solrconfig.xml,x.xml,y.xml</str>This ensures that the local configuration solrconfig_slave.xml will be saved as solrconfig.xml on the slave. All other files will be saved with their original names.
On the master server, the file name of the slave configuration file can be anything, as long as the name is correctly identified in the confFiles string; then it will be saved as whatever file name appears after the colon ':'.
Configuring the Replication RequestHandler on a Slave Server
The code below shows how to configure a ReplicationHandler on a slave.
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<!-- fully qualified url for the replication handler of master. It is
possible to pass on this as a request param for the fetchindex command -->
<str name="masterUrl">http://remote_host:port/solr/core_name/replication</str>
<!-- Interval in which the slave should poll master. Format is HH:mm:ss .
If this is absent slave does not poll automatically.
But a fetchindex can be triggered from the admin or the http API -->
<str name="pollInterval">00:00:20</str>
<!-- THE FOLLOWING PARAMETERS ARE USUALLY NOT REQUIRED-->
<!-- To use compression while transferring the index files. The possible
values are internal|external. If the value is 'external' make sure
that your master Solr has the settings to honor the accept-encoding header.
See here for details: http://wiki.apache.org/solr/SolrHttpCompression
If it is 'internal' everything will be taken care of automatically.
USE THIS ONLY IF YOUR BANDWIDTH IS LOW.
THIS CAN ACTUALLY SLOWDOWN REPLICATION IN A LAN -->
<str name="compression">internal</str>
<!-- The following values are used when the slave connects to the master to
download the index files. Default values implicitly set as 5000ms and
10000ms respectively. The user DOES NOT need to specify these unless the
bandwidth is extremely low or if there is an extremely high latency -->
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<!-- If HTTP Basic authentication is enabled on the master, then the slave
can be configured with the following -->
<str name="httpBasicAuthUser">username</str>
<str name="httpBasicAuthPassword">password</str>
</lst>
</requestHandler>Setting Up a Repeater with the ReplicationHandler
A master may be able to serve only so many slaves without affecting performance. Some organizations have deployed slave servers across multiple data centers. If each slave downloads the index from a remote data center, the resulting download may consume too much network bandwidth. To avoid performance degradation in cases like this, you can configure one or more slaves as repeaters. A repeater is simply a node that acts as both a master and a slave.
-
To configure a server as a repeater, the definition of the Replication
requestHandlerin thesolrconfig.xmlfile must include file lists of use for both masters and slaves. -
Be sure to set the
replicateAfterparameter to commit, even ifreplicateAfteris set to optimize on the main master. This is because on a repeater (or any slave), a commit is called only after the index is downloaded. The optimize command is never called on slaves. -
Optionally, one can configure the repeater to fetch compressed files from the master through the compression parameter to reduce the index download time.
Here is an example of a ReplicationHandler configuration for a repeater:
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="master">
<str name="replicateAfter">commit</str>
<str name="confFiles">schema.xml,stopwords.txt,synonyms.txt</str>
</lst>
<lst name="slave">
<str name="masterUrl">http://master.solr.company.com:8983/solr/core_name/replication</str>
<str name="pollInterval">00:00:60</str>
</lst>
</requestHandler>Commit and Optimize Operations
When a commit or optimize operation is performed on the master, the RequestHandler reads the list of file names which are associated with each commit point. This relies on the replicateAfter parameter in the configuration to decide which types of events should trigger replication.
These operations are supported:
-
commit: Triggers replication whenever a commit is performed on the master index. -
optimize: Triggers replication whenever the master index is optimized. -
startup: Triggers replication whenever the master index starts up.
The replicateAfter parameter can accept multiple arguments. For example:
<str name="replicateAfter">startup</str>
<str name="replicateAfter">commit</str>
<str name="replicateAfter">optimize</str>Slave Replication
The master is totally unaware of the slaves.
The slave continuously keeps polling the master (depending on the pollInterval parameter) to check the current index version of the master. If the slave finds out that the master has a newer version of the index it initiates a replication process. The steps are as follows:
-
The slave issues a
filelistcommand to get the list of the files. This command returns the names of the files as well as some metadata (for example, size, a lastmodified timestamp, an alias if any). -
The slave checks with its own index if it has any of those files in the local index. It then runs the filecontent command to download the missing files. This uses a custom format (akin to the HTTP chunked encoding) to download the full content or a part of each file. If the connection breaks in between, the download resumes from the point it failed. At any point, the slave tries 5 times before giving up a replication altogether.
-
The files are downloaded into a temp directory, so that if either the slave or the master crashes during the download process, no files will be corrupted. Instead, the current replication will simply abort.
-
After the download completes, all the new files are moved to the live index directory and the file’s timestamp is same as its counterpart on the master.
-
A commit command is issued on the slave by the Slave’s ReplicationHandler and the new index is loaded.
Replicating Configuration Files
To replicate configuration files, list them using using the confFiles parameter. Only files found in the conf directory of the master’s Solr instance will be replicated.
Solr replicates configuration files only when the index itself is replicated. That means even if a configuration file is changed on the master, that file will be replicated only after there is a new commit/optimize on master’s index.
Unlike the index files, where the timestamp is good enough to figure out if they are identical, configuration files are compared against their checksum. The schema.xml files (on master and slave) are judged to be identical if their checksums are identical.
As a precaution when replicating configuration files, Solr copies configuration files to a temporary directory before moving them into their ultimate location in the conf directory. The old configuration files are then renamed and kept in the same conf/ directory. The ReplicationHandler does not automatically clean up these old files.
If a replication involved downloading of at least one configuration file, the ReplicationHandler issues a core-reload command instead of a commit command.
Resolving Corruption Issues on Slave Servers
If documents are added to the slave, then the slave is no longer in sync with its master. However, the slave will not undertake any action to put itself in sync, until the master has new index data.
When a commit operation takes place on the master, the index version of the master becomes different from that of the slave. The slave then fetches the list of files and finds that some of the files present on the master are also present in the local index but with different sizes and timestamps. This means that the master and slave have incompatible indexes.
To correct this problem, the slave then copies all the index files from master to a new index directory and asks the core to load the fresh index from the new directory.
HTTP API Commands for the ReplicationHandler
You can use the HTTP commands below to control the ReplicationHandler’s operations.
enablereplication-
Enable replication on the "master" for all its slaves.
http://_master_host:port_/solr/_core_name_/replication?command=enablereplication disablereplication-
Disable replication on the master for all its slaves.
http://_master_host:port_/solr/_core_name_/replication?command=disablereplication indexversion-
Return the version of the latest replicatable index on the specified master or slave.
http://_host:port_/solr/_core_name_/replication?command=indexversion fetchindex-
Force the specified slave to fetch a copy of the index from its master.
http://_slave_host:port_/solr/_core_name_/replication?command=fetchindexIf you like, you can pass an extra attribute such as
masterUrlorcompression(or any other parameter which is specified in the<lst name="slave">tag) to do a one time replication from a master. This obviates the need for hard-coding the master in the slave. abortfetch-
Abort copying an index from a master to the specified slave.
http://_slave_host:port_/solr/_core_name_/replication?command=abortfetch enablepoll-
Enable the specified slave to poll for changes on the master.
http://_slave_host:port_/solr/_core_name_/replication?command=enablepoll disablepoll-
Disable the specified slave from polling for changes on the master.
http://_slave_host:port_/solr/_core_name_/replication?command=disablepoll details-
Retrieve configuration details and current status.
http://_slave_host:port_/solr/_core_name_/replication?command=details filelist-
Retrieve a list of Lucene files present in the specified host’s index.
http://_host:port_/solr/_core_name_/replication?command=filelist&generation=<_generation-number_>You can discover the generation number of the index by running the
indexversioncommand. backup-
Create a backup on master if there are committed index data in the server; otherwise, does nothing.
http://_master_host:port_/solr/_core_name_/replication?command=backupThis command is useful for making periodic backups. There are several supported request parameters:
-
numberToKeep:: This can be used with the backup command unless themaxNumberOfBackupsinitialization parameter has been specified on the handler – in which casemaxNumberOfBackupsis always used and attempts to use thenumberToKeeprequest parameter will cause an error. -
name: (optional) Backup name. The snapshot will be created in a directory calledsnapshot.<name>within the data directory of the core. By default the name is generated using date inyyyyMMddHHmmssSSSformat. Iflocationparameter is passed, that would be used instead of the data directory -
location: Backup location.
-
deletebackup-
Delete any backup created using the
backupcommand.http://_master_host:port_ /solr/_core_name_/replication?command=deletebackupThere are two supported parameters:
-
name: The name of the snapshot. A snapshot with the namesnapshot.namemust exist. If not, an error is thrown. -
location: Location where the snapshot is created.
-
Distribution and Optimization
Optimizing an index is not something most users should generally worry about - but in particular users should be aware of the impacts of optimizing an index when using the ReplicationHandler.
The time required to optimize a master index can vary dramatically. A small index may be optimized in minutes. A very large index may take hours. The variables include the size of the index and the speed of the hardware.
Distributing a newly optimized index may take only a few minutes or up to an hour or more, again depending on the size of the index and the performance capabilities of network connections and disks. During optimization the machine is under load and does not process queries very well. Given a schedule of updates being driven a few times an hour to the slaves, we cannot run an optimize with every committed snapshot.
Copying an optimized index means that the entire index will need to be transferred during the next snappull. This is a large expense, but not nearly as huge as running the optimize everywhere.
Consider this example: on a three-slave one-master configuration, distributing a newly-optimized index takes approximately 80 seconds total. Rolling the change across a tier would require approximately ten minutes per machine (or machine group). If this optimize were rolled across the query tier, and if each slave node being optimized were disabled and not receiving queries, a rollout would take at least twenty minutes and potentially as long as an hour and a half. Additionally, the files would need to be synchronized so that the following the optimize, snappull would not think that the independently optimized files were different in any way. This would also leave the door open to independent corruption of indexes instead of each being a perfect copy of the master.
Optimizing on the master allows for a straight-forward optimization operation. No query slaves need to be taken out of service. The optimized index can be distributed in the background as queries are being normally serviced. The optimization can occur at any time convenient to the application providing index updates.
While optimizing may have some benefits in some situations, a rapidly changing index will not retain those benefits for long, and since optimization is an intensive process, it may be better to consider other options, such as lowering the merge factor (discussed in the section on Index Configuration).
| Do not elect to optimize your index unless you have tangible evidence that it will significantly improve your search performance. Recent changes in Solr/Lucene have dramatically lessened the need to optimize as discussed at the above link. |
We welcome feedback on Solr documentation. However, we cannot provide application support via comments. If you need help, please send a message to the Solr User mailing list.